
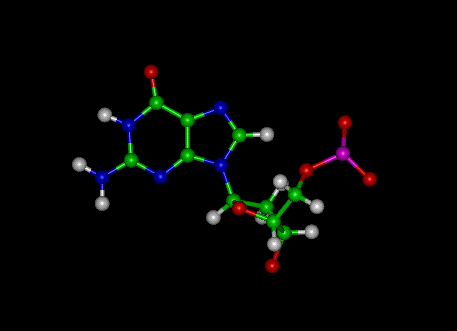
Guanine (2-amino-6-oxypurine) is one of the four main nitrogenous bases found in nucleic acids (e.g., DNA and RNA).
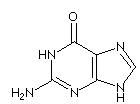
Guanine is a purine derivative and in Watson-Crick base pairing forms hydrogen bonds with cytosine. The nucleoside is called guanosine.
Guanine is also the name of a white amorphous substance found in the scales of certain fishes, the guano of sea-birds, and the liver and pancreas of mammals.